欢迎,来自IP地址为:216.73.217.64 的朋友
教程 开始之前,我们需要首先了解一下什么是Excel,这有助于理解之后教程中的内容。
什么是Excel
- Excel 是微软出品的和款办公软件
- 它能够创建和编辑以”xls”和”xlsx”为后缀的电子表格文件
- Excel文件可以在Windows、macOS、Android和iOS系统中使用
- 自1993年发布5.0 版本以来,Excel 已经成为电子表格事实上的标准
Excel 的用途
- 绘图
- 数据透视表
- 单元格计算
当然,Excel常常被用于办公,制作各种各样的报表。
为什么要选择Excel
虽然市面上有很多电子表格工具可以选择,但是Excel以其丰富的功能被大家所接受,并且由于众多企业用户都使用Excel,这令其更具竞争优势。
Python读取Excel文件教程
现在,我们将演示如何使用Python语言读取Excel文件内容。或许你会觉得这样读取Excel文件内容是非常困难的,事实并非如此,我们将逐步实现它。
1. 创建一个新项目
首先,创建一个项目,然后在项目文件夹添加一个名为”read_excel.py”的文件
2. 创建一个Excel文件
为了演示起见,我们创建一个名为”books.xls”的Excel文件,其内容如下:
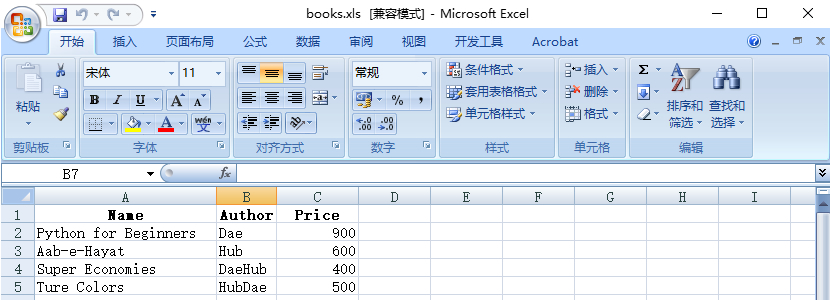
可以看到,该Excel文件包含了一些图书的基本信息,我们平时也是这样使用Excel的。
3. 安装Python 库
现在需要做的就是安装可以读取Excel文件内容的Python库,当然有很多库都可以完成此项工作,这里我们选择比较常用的pandas库。使用pandas库有以下几个原因:
- Pandas 是基本NumPy 的软件库,可以提供易于使用的Python 数据结构和数据分析工具
- Pandas 不仅强大而且非常灵活,经常被用于数据分析
要安装Pandas库,可以使用如下命令:
pip install pandas
为了从读取Excel电子表格中的数据,我们还需要使用xlrd库,当然pip安装即可:
pip install xlrd
4. 读取Excel文件
现在,我们编写一段代码来读取”books.xls”文件中的内容:
import pandas as pd file = "books.xls" data = pd.read_excel(file) #reading file print(data)
代码解释:
- 首先引入pandas模块
- 初始化一个变量”file”用于存储Excel文件名,注意示例并没有给出确切的文件路径,只使用了文件名,那么系统会默认使用当前路径,也就是将”books.xls”放置于项目文件夹同”read_excel.py”位于同一目录即可
- 调用pandas模板的read_excel方法,将”books.xls”中的内容读取到变量data
- 最后在终端将data变量的内容打印出来
一切正常的话,会在终端显示如下结果:
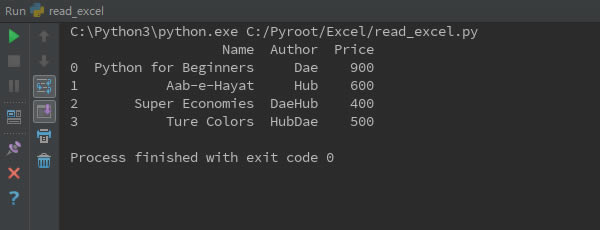
5. 修改读取内容
如果想修改从Excel文件中读取的内容,例如将”Author”中值为”HubDae”的修改为”Daehub”,则可以参照如下代码:
import pandas as pd
file = "books.xls"
def convert_author_cell(cell):
if cell == "HubDae":
return 'Daehub'
return cell
data = pd.read_excel(file,converters={'Author':convert_author_cell})
print(data)
代码解释:
- 首先定义一下转换单元格内容函数”convert_author_cell(cell)”,该函数以读取的单元格为参数,返回值同样为单元格
- 通过”convert_author_cell(cell)”函数将读取的单元格内容进行转换
- 再次调用”read_excel”方法读取Excel文件,同时添加converters参数,其参数值采用Python字典类型,键为Excel字段名,值为对应单元格的值
- 在读取Excel文件时,会对”Author”字段调用”convert_author_cell(cell)”函数
执行代码后,会看到如下结果:
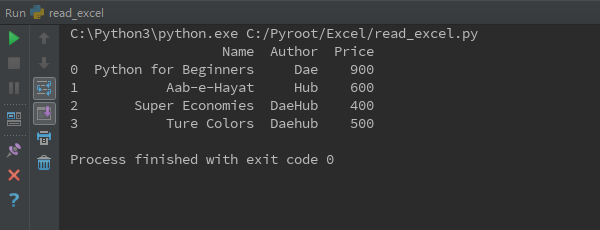
可以看到,此时读取到的Excel文件内容发生了转换。但这只是对内存中的数据进行了修改,并没有改变文件本身的内容。可以用Excel软件打开”books.xls”文件,发现此时其内容并没有发生变化。
6. Python写入Excel文件
进一步,我们将学习如何使用Python将数据写入Excel文件。这需要使用到”xlwt”,我们同样使用pip进行安装:
pip install xlwt
- xlwt是用于创建兼容Excel 2003的软件包
- xlwt本身是由Python标准包编写完成,不需要其他任何依赖包
现在,我们编写一个简单的创建Excel文件的程序段:
import pandas as pd
file = "books.xls"
data = pd.read_excel(file)
#writing excel file
data.to_excel("new.xls", sheet_name="Student")
代码解释:
- 为了写入Excel文件,需要调用”to_excel”方法
- 该方法接受两个参数,其中一个为写入的文件名,示例为”new.xls”,另一个为工作薄名也就是Excel中的sheet名,示例为”Student”
执行这段代码后,会在当前项目文件夹创建一个名为”new.xls”的文件,其内容和”books.xls”略有不同:
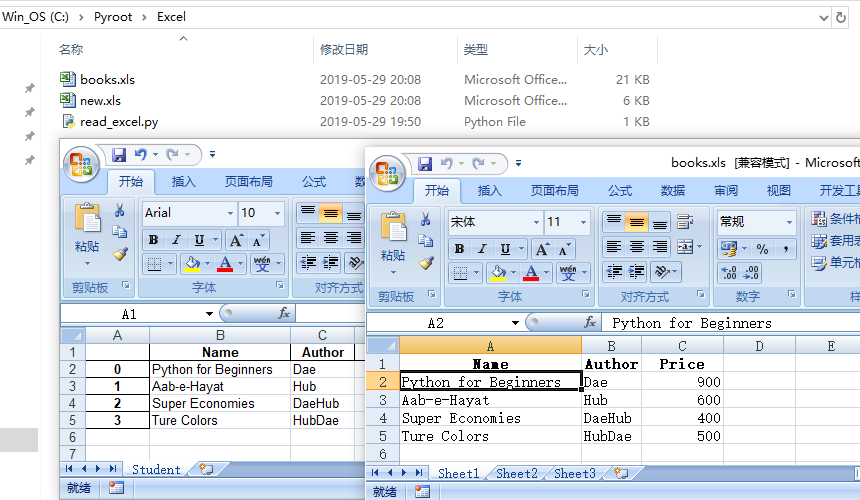
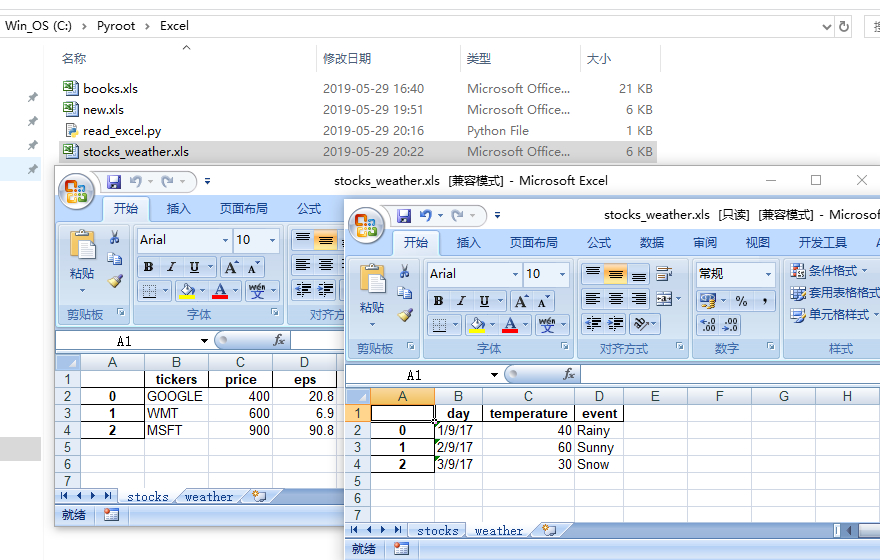
7. 将不同数据段数据写入同一个Excel文件中的不同工作薄
以下代码是将不同数据段数据写入同一个Excel文件中的不同工作薄示例,需要使用”DataFrame”方法:
import pandas as pd
#creating dataframes
df_stock = pd.DataFrame({
'tickers':['GOOGLE','WMT','MSFT'],
'price':[400,600,900],
'eps':[20.80,6.90,90.8]
})
df_weather = pd.DataFrame({
'day':['1/9/17','2/9/17','3/9/17'],
'temperature':[40,60,30],
'event':['Rainy','Sunny','Snow']
})
with pd.ExcelWriter('stocks_weather.xls') as writer:
df_stock.to_excel(writer,sheet_name="stocks")
df_weather.to_excel(writer,"weather")
代码解释:
- 首先调用DataFrame方法创建两个数据对象
- 然后调用ExcelWriter方法创建一个写Excel文件对象
- 最后调用数据对象的to_excel方法将数据写入到Excel文件中,并且将对应的工作薄命名为”stocks”和”weather”
代码执行成功后,会在项目文件夹创建一个名为”stocks_weather.xls”的文件,包含两个工作薄,如下图所示:
以上就是Python读写Excel文件的简单教程。
