欢迎,来自IP地址为:216.73.216.63 的朋友
JSON 自推出以来,已迅速成为数据交换的主要标准。无论是使用 API 传输数据还是将数据存储在文档数据库中,都可能需要使用 JSON。幸运的是,Python 提供了强大的工具来帮助我们高效地管理使用 JSON 数据。
虽然 JSON 是数据分发的最常见格式,但它并不是此类任务的唯一选择。XML 和 YAML 也可实现类似功能。
JSON 简介
JSON 是 JavaScript Object Notation 的首母缩写。顾名思义,JSON 起源于 JavaScript。然而,JSON 已经超越了其起源,成为与语言无关的数据表示方法,现在被公认为数据交换的标准。
JSON 的流行可以归因于 JavaScript 语言的原生支持,从而在 Web 浏览器中具有出色的解析性能。最重要的是,JSON 的简单语法使人类和计算机都可以轻松地读取和写入 JSON 数据。
要对 JSON 有一个初步印象,请看如下示例:
{
"greeting": "Hello, world!"
}
我们将在本教程后面了解有关 JSON 语法的更多内容。现在,只需要认识到 JSON 格式是基于文本的。
换句话说,可以使用代码编辑器创建 JSON 文件。在将文件扩展名设置为”.json”后,大多数代码编辑器都会立即显示 JSON 数据并突出显示语法。

JSON 语法
通过上面的内容,我们对 JSON 数据有了初步印象。作为 Python 开发人员,JSON 结构可能会让我们联想起常见的 Python 数据结构,例如包含字符串作为键和值的字典。如果了解 Python 中字典的语法,那么就已经知道 JSON 对象的一般语法。
Python 字典和 JSON 对象之间的相似性并不令人意外。将 JSON 确立为首选数据交换格式背后的一个想法是让 JSON 的使用尽可能方便,而不管使用哪种编程语言:
[键值对和数组的集合] 是通用数据结构,几乎所有现代编程语言都以某种形式支持它们。与编程语言可互换的数据格式也基于这些结构是有道理的。>> 出处 <<
为了进一步探索 JSON 语法,创建一个名为”hello_frieda.json”的新文件,并添加更复杂的 JSON 结构作为文件内容:
{
"name": "Frieda",
"isDog": true,
"hobbies": ["eating", "sleeping", "barking"],
"age": 8,
"address": {
"work": null,
"home": ["Beijing", "China"]
},
"friends": [
{
"name": "Philipp",
"hobbies": ["eating", "sleeping", "reading"]
},
{
"name": "Mitch",
"hobbies": ["running", "snacking"]
}
]
}
上面的示例代码,是关于一只名叫”Frieda”的狗的数据,格式为 JSON。顶级值是一个 JSON 对象,就像 Python 字典一样,需要将 JSON 对象包裹在花括号”{}”内。
在第 1 行中,我们以左花括号”{“开始 JSON 对象,然后在最后一行末尾以右花括号”}” 结束该对象。
注意:虽然 JSON 中的空格无关紧要,但 JSON 文档的格式通常为两个或四个空格,以表示缩进。如果 JSON 文档的文件大小很重要,那么可以考虑删除空格来缩小 JSON 文件。
在 JSON 对象中,可以定义零个、一个或多个键值对。如果包含多个键值对,则必须用逗号”,”分隔它们。
JSON 对象中的键值对由冒号”:”分隔。在冒号的左侧,可以定义一个键。键是一个必须用双引号”” 括起来的字符串。与 Python 不同,JSON 字符串是不支持单引号”的。
JSON 文档中的值仅限于以下数据类型:
| JSON 数据类型 | 描述 |
|---|---|
| object | 对象,用花括号”{}”内的键值对集合 |
| array | 数组,用方括号”[]”括起来的值列表 |
| string | 字符串,用双引号””括起来的文本 |
| number | 数值,整数或浮点数 |
| boolean | 布尔值,不带引号,为真或假 |
| null | 表示空值,写为null |
就像在字典和列表中一样,可以在 JSON 对象和数组中嵌套数据。例如,我们可以将对象作为对象的值。此外,还可以自由地使用任何其他允许的值作为 JSON 数组中的项。
作为 Python 开发人员,需要特别注意布尔值。不要使用首字母大写的 True 或 False,而必须使用小写的 JavaScript 样式布尔值 true 或 false。
接下来我们了解一下 JSON 在使用过程中常常会遇到的语法问题。
JSON 标准不允许字符串使用任何注释、尾随逗号或单引号。这可能会让习惯使用 Python 字典或 JavaScript 对象的开发人员感到困惑。
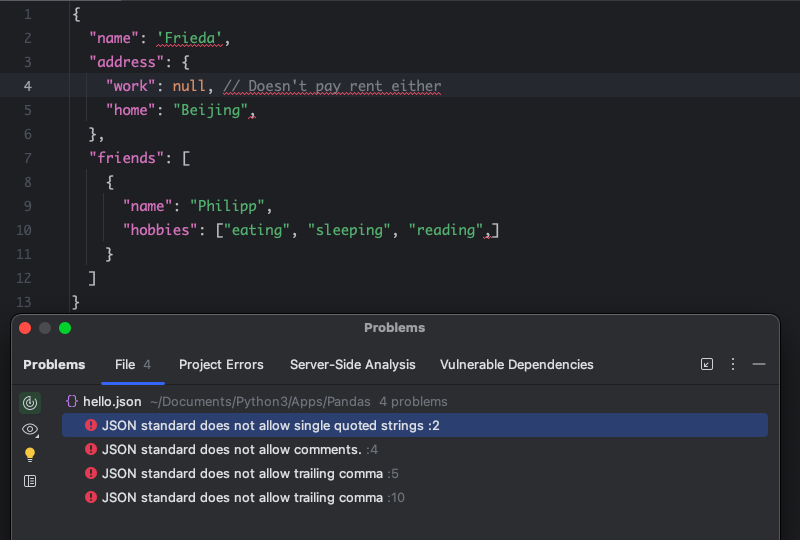
作为一名 Python 开发人员,使用双引号是可以习惯的。注释有助于解释代码,尾随逗号可以使代码中的行移动更轻松。
如果想编写有效的 JSON,那么编码编辑器会大有帮助。上面的无效 JSON 文档包含每个不正确 JSON 语法都会被标记出来。
如果不想使用代码编辑器,我们还可以使用在线工具来验证编写的 JSON 语法是否正确。用于验证 JSON 的流行在线工具是 >>JSON Lint<< 和 >>JSON Formatter<<。
现在,是时候了解如何在 Python 中处理 JSON 数据了。
Python 写入 JSON
Python 通过名为 json 的内置模块支持 JSON 格式。json 模块专门用于读取和写入 JSON 格式的字符串。这意味着可以方便地将 Python 数据类型转换为 JSON 数据,反之亦然。
将 Python 数据转换为 JSON 格式的操作称为序列化。此过程涉及将数据转换为一系列字节以进行存储或通过网络传输。相反的过程,即反序列化,涉及将 JSON 格式的数据解码回 Python 中可用的数据结构。
首先,在 json 模块的帮助下将 Python 代码序列化为 JSON 数据。
将 Python 字典转换为 JSON 数据
在 Python 中使用 JSON 时最常见的操作之一是将 Python 字典转换为 JSON 对象。
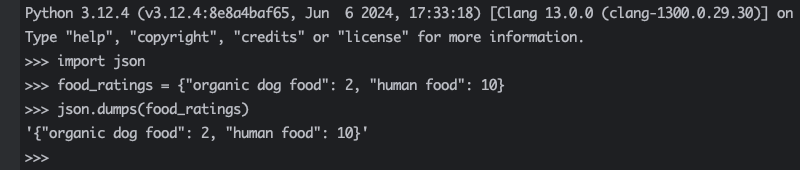
导入 json 模块后,我们可以使用”dumps()”函数将 Python 字典转换为 JSON 格式的字符串,该字符串表示 JSON 对象。
需要强调的是,当使用”dumps()”时,会得到一个 Python 字符串。换句话说,这不会创建任何类型的 JSON 数据类型。其结果类似于使用 Python 的内置 str() 函数时得到的结果。
当 Python 字典不包含字符串作为键或者值不能直接转换为 JSON 格式时,使用 json.dumps() 会变得更有趣:

可以看到,在 numbers_present 字典中,键 1、2 和 3 是数字。使用”dumps()”后,字典键将变为 JSON 格式的键值字符串。
字典的 Python 布尔值将变为 JSON 布尔值。如前所述,JSON 布尔值和 Python 布尔值之间微小但重要的区别在于 JSON 布尔值是小写的。
Python 的 json 模块的妙处还在于它会为您处理转换。当在字典中使用变量时,它同样会派上用场:

当将 Python 数据类型转换为 JSON 时,json 模块会接收求值。在此过程中,json 严格遵循 JSON 标准。例如,将整数键(如 1)转换为字符串”1″。
其他 Python 数据类型序列化为 JSON
json 模块允许将常见的 Python 数据类型转换为 JSON。以下是可以转换为 JSON 值的所有 Python 数据类型和值的概述:
| Python 数据类型 | JSON 数据类型 |
|---|---|
| dict | object |
| list | array |
| tuple | array |
| str | string |
| int | number |
| float | number |
| True | true |
| False | false |
| None | null |
需要注意的是,不同的 Python 数据类型(如列表和元组)会序列化为相同的 JSON 数组数据类型。此时若将 JSON 数据转换回 Python 时,这可能会导致问题,因为数据类型可能与之前不同。我们之后会讲解如何避免遇到类似问题
字典可能是我们在 JSON 中用作顶级值的最常见的 Python 数据类型。但同样可以使用 json.dumps() 像转换字典一样顺利地转换上面列出的数据类型。以布尔值或列表为例:

JSON 文档可能在顶层包含单个标量值(例如数字)。这仍然是有效的 JSON。但通常情况下,我们需要使用键值对的集合。与并非每种数据类型都可以用作 Python 中的字典键类似,并非所有键都可以转换为 JSON 键字符串:
| Python 数据类型 | 是否可以作为 JSON 键 |
|---|---|
| dict | × |
| list | × |
| tuple | × |
| str | √ |
| int | √ |
| float | √ |
| True | √ |
| False | √ |
| None | √ |
不能使用字典、列表或元组作为 JSON 键。对于字典和列表,此规则是有意义的,因为它们不可哈希。但即使元组可哈希且允许作为字典中的键,仍然不可以转换成 JSON 键。
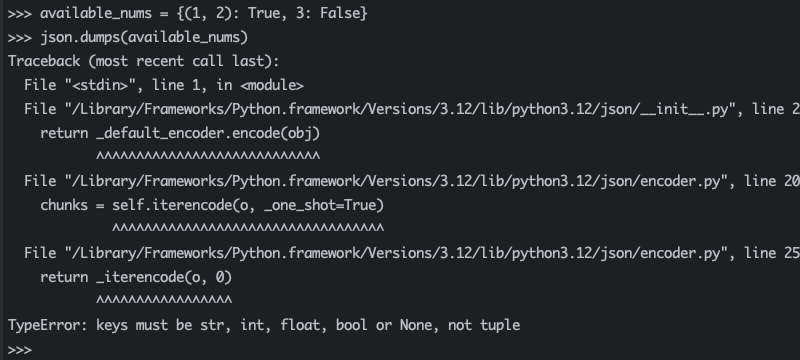
通过给函数提供 skipkeys 参数,就可以避免在使用不受支持的 Python 键创建 JSON 数据时出现 TypeError:

当将 json.dumps() 中的 skipkeys 设置为 True 时,Python 会跳过不受支持的键,否则会引发 TypeError。结果是一个 JSON 格式的字符串,其中仅包含输入字典的子集。实际使用过程中,我们通常希望 JSON 数据尽可能接近输入对象。因此,在调用 json.dumps() 时必须谨慎使用 skipkeys,以免丢失信息。
使用 json.dumps() 时,可以使用其他参数来控制生成的 JSON 格式字符串的外观。例如,可以通过将 sort_keys 参数设置为 True 来对字典键进行排序:

将 sort_keys 设置为 True 时,Python 会在序列化字典时按字母顺序对键进行排序。当字典键以前表示数据库的列名,并且如果希望以有组织的方式向用户显示它们时,对 JSON 对象的键进行排序会很方便。
json.dumps() 的另一个值得注意的参数是 indent,在序列化 JSON 数据时,我们可能最常使用它。后面将在美化 JSON 时介绍它。
当我们将 Python 数据类型转换为 JSON 格式时,通常还需要做其它操作。最常见的是,就是使用 JSON 来保存和交换数据。为此,需要在正在运行的 Python 程序之外保存 JSON 数据。接下来我们讲解如何保存 JSON 数据。
Python 输出 JSON 文件
当我们想要在 Python 程序之外保存数据时,JSON 格式会派上用场。例如可能想使用 JSON 文件来存储工作流数据,而不是启动数据库。同样,Python 可以满足我们的需求。
要将 Python 数据写入外部 JSON 文件,则使用 json.dump()。这是一个与之前看到的函数类似的函数,但其名称末尾没有 s:
import json
dog_data = {
"name": "Frieda",
"is_dog": True,
"hobbies": ["eating", "sleeping", "barking"],
"age": 8,
"address": {
"work": None,
"home": ("Beijing", "China")
},
"friends": [
{
"name": "Philipp",
"hobbies": ["eating", "sleeping", "reading",],
},
{
"name": "Mitch",
"hobbies": ["running", "snacking",],
},
],
}
with open("hello_frieda.json", mode="w", encoding="utf-8") as write_file:
json.dump(dog_data, write_file)
示例代码首先定义了一个 dog_data 字典,并使用上下文管理器将其写入 JSON 文件”hello_frieda.json”。为了正确指示文件包含 JSON 数据,我们将文件扩展名设置为 .json。
使用 open() 时,预先定义字符集编码是一种很好的做法。对于 JSON,在读取和写入文件时,通常使用“utf-8”作为编码:
RFC 要求 JSON 使用 UTF-8、UTF-16 或 UTF-32 表示,其中 UTF-8 是推荐的默认值,以实现最大互操作性。
json.dump() 函数有两个必需参数:
- 要写入的对象
- 要写入的文件
除此之外,json.dump() 还有一堆可选参数。json.dump() 的可选参数与 json.dumps() 的相同。将在本教程后面的美化和缩小 JSON 时统一说明。
Python 读取 JSON
在前面部分中,我们了解了如何将 Python 数据序列化为 JSON 格式的字符串和 JSON 文件。现在,我们将看到将 JSON 数据重新加载到 Python 程序中时会发生什么。
除了 json.dumps() 和 json.dump() 之外,json 库还提供了两个函数来将 JSON 数据反序列化为 Python 对象:
- json.loads():反序列化字符串、字节或字节数组实例
- json.load():反序列化文本文件或二进制文件
根据经验,当数据已存在于 Python 程序中时,可以使用 json.loads();需要使用 json.load() 用于读取保存在磁盘上的文件。
从 JSON 数据类型和值到 Python 的转换遵循与之前将 Python 对象转换为 JSON 格式时类似的映射:
| JSON 数据类型 | Python 数据类型 |
|---|---|
| object | dict |
| array | list |
| str | string |
| number | int |
| number | float |
| true | True |
| false | False |
| null | None |
将此表与前面的表进行比较,我们会发现 Python 为所有 JSON 类型提供了匹配的数据类型。这非常方便,因为这样,就可以确保在将 JSON 数据反序列化为 Python 时不会丢失任何信息。
注意:反序列化并不是序列化过程的完全逆过程。原因是 JSON 键始终是字符串,并且并非所有 Python 数据类型都可以转换为 JSON 数据类型。这种差异意味着某些 Python 对象在序列化然后反序列化时可能无法保留其原始类型。
为了更好地理解数据类型的转换,我们首先将 Python 对象序列化为 JSON,然后将 JSON 数据转换回 Python。这样,就可以发现序列化的 Python 对象与反序列化 JSON 数据后得到的 Python 对象之间的差异。
将 JSON 对象转换为 Python 字典
要了解如何从 JSON 对象加载成 Python 字典,请重新查看之前的示例。首先创建一个 dog_registry 字典,然后使用 json.dumps() 将 Python 字典序列化为 JSON 字符串。
import json
dog_registry = {1: {"name": "Frieda"}}
dog_json = json.dumps(dog_registry)
print(dog_json)
通过将 dog_registry 传递到 json.dumps(),您将创建一个包含 JSON 对象的字符串,并将其保存在 dog_json 中。如果您想将 dog_json 转换回 Python 字典,则可以使用 json.loads():
new_dog_registry = json.loads(dog_json)
通过使用 json.loads(),你可以将 JSON 数据转换回 Python 对象。凭借迄今为止获得的有关 JSON 的知识,你可能已经怀疑 new_dog_registry 字典的内容与 dog_registry 的内容并不相同:
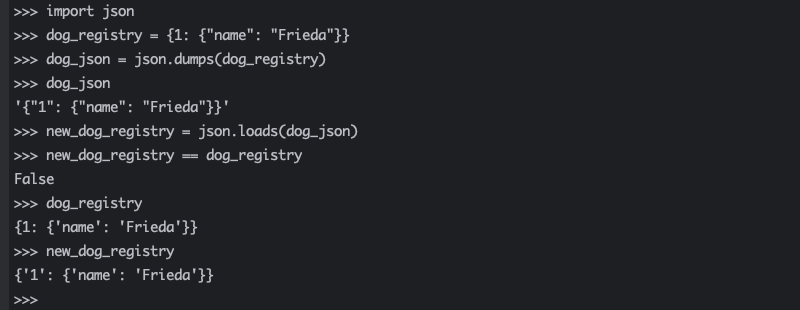
new_dog_registry 和 dog_registry 之间的区别很微妙,但会对 Python 程序产生影响。在 JSON 中,键必须始终是字符串。使用 json.dumps() 将 dog_registry 转换为 dog_json 时,整数键 1 变为字符串”1″。再使用 json.loads() 时,Python 无法知道字符串键应该再次是整数。这就是为什么这个字典键在反序列化后仍然是字符串的原因。
我们将通过对其他 Python 数据类型进行另一次转换往返来调查类似的行为。
import json
dog_data = {
"name": "Frieda",
"is_dog": True,
"hobbies": ["eating", "sleeping", "barking"],
"age": 8,
"address": {
"work": None,
"home": ("Beijing", "China")
},
}
dog_data_json = json.dumps(dog_data)
new_dog_data = json.loads(dog_data_json)
print(new_dog_data)
print(type(dog_data["address"]["home"]))
print(type(new_dog_data["address"]["home"]))
dog_data 字典包含一堆常见的 Python 数据类型作为值。例如,表示名称的字符串、是否为狗的布尔值、表示工作内容的 NoneType 和表示住址的元组,仅举几例。
接下来,将 dog_data 转换为 JSON 格式的字符串,然后再转换回 Python。之后,查看新创建的字典:
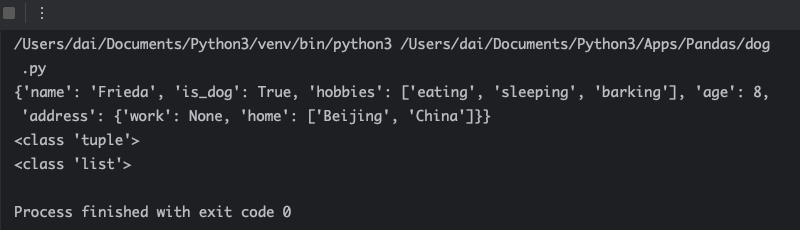
我闪可以将 JSON 数据类型完美地转换为匹配的 Python 数据类型:JSON 布尔值 true 反序列化为 True,null 转换回 None,对象和数组变为字典和列表。
不过,在往返过程中也可能会遇到一种例外情况,当序列化 Python 元组时,它会变成 JSON 数组。当加载 JSON 时,JSON 数组会正确地反序列化为列表,因为 Python 无法知道原始类型是数组还是元组。
当我们进行数据往返时,上述问题始终会成为问题。当往返发生在同一个程序中时,我们还有可能清楚预期的数据类型。但当处理源自另一个程序的外部 JSON 文件时,数据类型转换可能会更加模糊。
处理 JSON 文件
例如读取之前程序创建的 JSON 文件”hello_frieda.json”,当我们想要将内容写入 JSON 文件时,可以使用 json.dump()。json.dump() 的对应函数是 json.load()。顾名思义,我们可以使用 json.load() 将 JSON 文件加载到 Python 程序中:
import json
with open("hello_frieda.json", mode="r", encoding="utf-8") as read_file:
frie_data = json.load(read_file)
print(frie_data)
就像写入文件一样,在 Python 中读取文件时使用上下文管理器是个好主意。这样,就不必再费心关闭文件了。当我们想要读取 JSON 文件时,就可以在 with 语句的块中使用 json.load()函数。
load() 函数的参数必须是文本文件或二进制文件。从 json.load() 获取的 Python 对象取决于 JSON 文件的顶级数据类型。在这种情况下,JSON 文件在顶级包含一个对象,那么这个对象会被反序列化为 Python 字典。
当我们将 JSON 文件反序列化为 Python 对象时,还可以原生地与其交互。例如,通过使用方括号表示法”[]”访问”name”键的值。不过,这里还是要提醒一下,导入之前的原始 dog_data 字典与 frie_data 并不完全相同。
将 JSON 文件加载为 Python 对象时,任何 JSON 数据类型都可以顺利地反序列化为 Python。这是因为 Python 知道 JSON 格式支持的所有数据类型。不幸的是,反过来就不一样了。
正如之前所了解的,我们可以将 Python 数据类型(如 tuple)转换为 JSON,但 JSON 文件中最终会得到数组数据类型。将 JSON 数据转换回 Python 后,数组将反序列化为 Python 列表数据类型。
通常,谨慎处理数据类型转换应该是编写处理 JSON 数据的 Python 程序的关注点。凭借对于 JSON 文件的了解,只要 JSON 文件有效,我们始终可以预测最终会得到哪些 Python 数据类型。
在使用 json.load()时,加载的文件的内容必须包含有效的 JSON 语法。否则,将得到 JSONDecodeError 报错。幸运的是,Python 提供了更多可用于与 JSON 交互的工具。例如,它允许我们从终端方便地检查 JSON 文件的有效性。
与 JSON 交互
到目前为止,我们已经探索了 JSON 语法,并讨论了一些常见的 JSON 使用问题,例如字符串的尾随逗号和单引号。在编写 JSON 时,我们可能还发现了一些令人讨厌的细节。例如,整齐缩进的 Python 字典最终会变成一团 JSON 数据。
现在,我们将尝试一些技术,在 Python 中处理 JSON 数据时更加轻松。
首先,我们将为我们的 JSON 对象赋予应有的光彩。
使用 Python 美化 JSON
JSON 格式的一大优势是 JSON 数据是人类可读的。更重要的是,JSON 数据是人类可写的。这意味着可以在我们最喜欢的文本编辑器中打开 JSON 文件并根据自己的喜好更改内容。
但是如果我们的的 JSON 数据在文本编辑器中如下所示时,手动编辑 JSON 数据就会变得非常麻烦:
{"name": "Frieda", "is_dog": true, "hobbies": ["eating", "sleeping", "barking"], "age": 8, "address": {"work": null, "home": ["Beijing", "China"]}}
即使启用了自动换行和语法高亮功能,当 JSON 数据只有一行代码时,它仍然很难阅读。作为一名 Python 开发人员,我们可能会错过一些空格。但不用担心,Python 已经为我们做好了相应对策。
当调用 json.dumps() 或 json.dump() 来序列化 Python 对象时,可以提供 indent 参数来设置缩进。可以尝试使用不同缩进级别的 json.dumps():
import json
dog_data = {
"name": "Frieda",
"age": 8
}
dog_data_json = json.dumps(dog_data, indent=0)
print(dog_data_json)
dog_data_json = json.dumps(dog_data, indent=-2)
print(dog_data_json)
dog_data_json = json.dumps(dog_data, indent="")
print(dog_data_json)
dog_data_json = json.dumps(dog_data, indent="⮑")
print(dog_data_json)

indent 的默认值为 None。当调用 json.dumps() 时,如果未使用 indent 或使用 None 作为值,将得到一行紧凑的 JSON 格式字符串。
如果希望 JSON 字符串中有换行符,则可以将 indent 设置为 0 或提供一个空字符串。尽管可能不太有用,但您甚至可以提供负数作为缩进或任何其他字符串。
最常见的是,为 indent 提供 2 或 4 这样的值。
当我们调用 json.dumps() 时使用正整数作为缩进值时,则将使用给定的缩进计数将 JSON 对象的每一级缩进为空格。此外,每个键值对都会有换行符。
indent 参数对于 json.dump() 的作用与对于 json.dumps() 的作用完全相同。以下语句会将 dog_friend 字典写入 JSON 文件,缩进 4 个空格:
with open("dog_friend.json", mode="w", encoding="utf-8") as write_file:
json.dump(dog_friend, write_file, indent=4)
在序列化 JSON 数据时设置缩进级别,最终会得到美化的 JSON 数据。
事实上,无论 JSON 文件如何缩进,Python 都可以正确处理它们。但作为人类,我们可能更喜欢包含换行符且缩进整齐的 JSON 文件。因为像这样的 JSON 文件编辑起来更方便。
使用 json.tool 处理 JSON
验证 JSON ovrn
要快速检查 JSON 文件是否有效,可以利用 Python 的 json.tool 工具。我们可以使用 -m 开关在终端中将 json.tool 模块作为可执行文件运行。要查看 json.tool 的实际操作,还需要提供 JSON 文件作为 infile 位置参数:
python -m json.tool ./hello_frieda.json
如果文件为正确的 JSON 格式文件,则会在终端中显示文件内容,如果文件中存在问题,则会显示相应错误。但请记住,json.tool 仅报告第一个错误。因此,如果想要查找到文件中所有问题,可能需要多次执行该命令。
终端中美化 JSON 显示
学会了使用 json.tool 验证了 JSON 文件后,当 JSON 语法有效时,json.tool 会显示带有换行符和四个空格缩进的内容。要控制 json.tool 如何打印 JSON,同样可以设置 –indent 选项。
python -m json.tool ./hello_frieda.json --indent 2
在终端中看到美化的 JSON 数据固然很不错,但是,我们还可以通过为 json.tool 运行提供另一个选项来进一步提升便利性。
默认情况下,json.tool 将输出写入 sys.stdout,就像我们调用 print() 函数时通常做的那样。我们也可以通过提供位置 outfile 参数将 json.tool 的输出重定向到文件中:
python -m json.tool hello_frieda.json pretty_frieda.json
使用 pretty_frieda.json 作为 outfile 选项的值,就可以将输出写入 JSON 文件,而不是在终端中显示内容。如果该文件尚不存在,则 Python 会在途中创建该文件。如果目标文件已存在,则使用新内容覆盖该文件。

当然,添加到 pretty_frieda.json 的空格是有代价的。与原始的未缩进的 hello_frieda.json 文件相比,pretty_frieda.json 的文件大小现在大约是原来的两倍。在这里,若干字节的增加可能并不重要。但是在处理大型 JSON 数据时,好看的 JSON 文件将占用相当多的存储空间。
在网络上提供数据时,拥有较小的数据占用空间尤其有用。由于 JSON 格式是通过网络交换数据的事实标准,因此值得将文件大小保持在尽可能小的范围内。
压缩 JSON 文件
想要压缩 JSON 文件,可以使用 json.tool 工具,也可以通过 Python 代码实现。
python -m json.tool pretty_frieda.json mini_frieda.json --compact
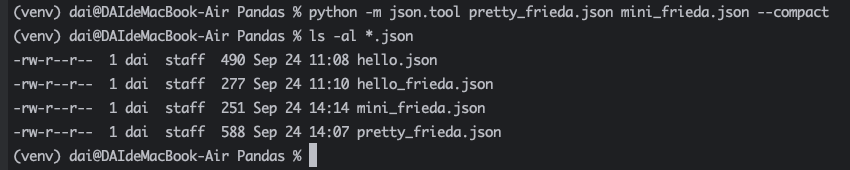
就像使用 –indent 一样,如果提供源文件和目标文件,就会输出压缩后的 JSON 文件。在上面的示例中,我们将 pretty_frieda.json 缩小为 mini_frieda.json。运行 ls 命令以查看从原始 JSON 文件中挤出了多少字节。
与 pretty_frieda.json 相比,mini_frieda.json 的文件大小小了不少。这甚至比不包含任何缩进的原始 hello_frieda.json 文件还小了。
要找到压缩后的文件小于原始文件的原因,就需要重新打开原始 json 文件。并通过如下代码实现同样的压缩操作:
import json
with open("hello_frieda.json", mode="r", encoding="utf-8") as input_file:
original_json = input_file.read()
json_data = json.loads(original_json)
mini_json = json.dumps(json_data, indent=None, separators=(",", ":"))
with open("mini_frieda_code.json", mode="w", encoding="utf-8") as output_file:
output_file.write(mini_json)
在上面的代码中,我们使用 Python 的 read() 获取 hello_frieda.json 的内容作为文本。然后,使用 json.loads() 将 original_json 反序列化为 json_data,这是一个 Python 字典。您可以使用 json.load() 立即获取 Python 字典,但您需要先将 JSON 数据作为字符串才能正确进行比较。
这也是为什么需要使用 json.dumps() 创建 mini_json,然后使用 write() 而不是直接利用 json.dump() 将缩小的 JSON 数据保存在 mini_frieda.json 中的原因。
如您之前所学,json.dumps 需要 JSON 数据作为第一个参数,然后接受缩进的值。 indent 的默认值为 None,因此您可以跳过像上面那样明确设置参数。但是使用 indent=None,您明确表示您不想要任何缩进,这对以后阅读代码的其他人来说是一件好事。
json.dumps() 的分隔符参数允许定义一个具有两个值的元组:
- 键值对或列表项之间的分隔符:默认情况下,此分隔符是逗号后跟空格(”, “)
- 键和值之间的分隔符:默认情况下,此分隔符是冒号后跟空格(”:”)
通过将分隔符设置为(”,”,”:”),就可以继续使用有效的 JSON 分隔符。此时会告诉 Python 不要在逗号(”,”)和冒号(”:”)后添加任何空格。这意味着 JSON 数据中剩下的唯一空格可能是键名和值中出现的空格。这样就会更为紧凑。
再次比较一下各文件的大小,就会对 JSON 的压缩有了进一步的理解。
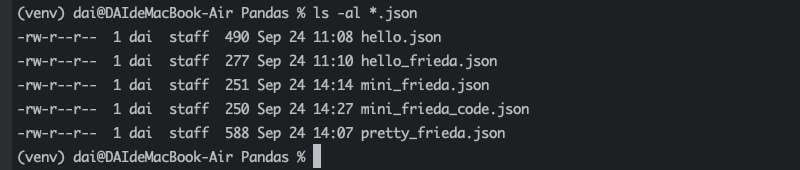
当查看输出时,就已经可以发现 original_json 和 mini_json 之间的差异。
然后,我们还可以使用 len() 函数来验证 mini_json 的大小。如果想知道为什么 JSON 字符串的长度几乎与写入文件的文件大小完全匹配,那么研究 Python 中的 Unicode 和字符编码是一个好主意。
当我们想要使 JSON 数据看起来更漂亮,或者想要缩小 JSON 数据以节省一些字节时,json 和 json.tool 都是很好的帮手。使用 json 模块,可以方便地在 Python 程序中与 JSON 数据交互。当需要更好地控制与 JSON 交互的方式时,这非常有用。如果想直接在终端中处理 JSON 数据时,json.tool 模块会派上用场。
无论是想使用 API 传输数据还是将信息存储在文档数据库中,都可能会遇到 JSON。
Python 提供了强大的工具来促进此过程并帮助我们高效管理 JSON 数据。在 Python 和 JSON 之间进行数据往返时,需要小心一些细节,因为它们不共享同一组数据类型。不过,JSON 格式是保存和交换数据的好方法。
